Searching the Accessory Genome
Calculating the accessory genome for a group of strains takes advantage of the genera’s wgMLST scheme. Such a scheme usually consists of over 20 000 genes (loci), which have been identified from a large diverse set of strains in the genera. Automatically in Enterobase, after a strain’ genome has been assembled, any wgMLST loci are identified and the information stored. The accessory genome is simply calculated as any loci that occur in at least in one strain in the group but less than 98%. Hence it is extremely quick to compute since the wgMLST loci are pre-calculated. However a disadvantage, is that loci not present in the wgMLST scheme will not be represented in accessory genome.
Obtaining an Accessory Genome
The Accessory Genome page can be reached from left hand menu under Tasks > Accessory Genome. In the top left hand panel click the ‘View Accessory Genome’ button and a dialog will show all the workspaces/tree that you have access to (workspaces can be created from the main search page of the database of interest). Select a tree/workspace that you want to create the accessory genome for and press load. Clicking on workspace will show any trees that are are part of the workspace. Trees or workspaces can be chosen, but if a tree is chosen, the genomes will be ordered by their position in the tree. At the moment only SNP Trees can be viewed- but it hoped that MS Trees will be displayed in the near future. When viewing an accessory genome for a tree/workspace for the first time, it may take a few seconds to calculate, but results are cached , so subsequent access should be quicker.
Viewing
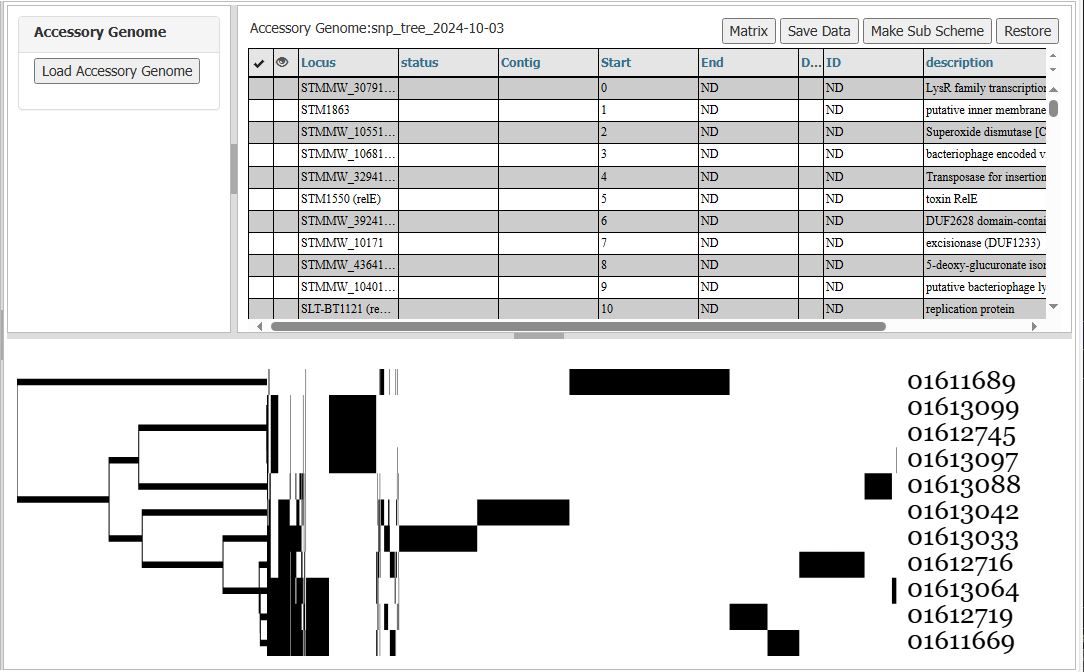
The graphic in the bottom panel contains three sections. The left hand section (1) shows the tree, but will be missing if a workspace is chosen. The right hand section shows the strain names(3) and the middle section the graph showing the presence/absence of loci. The x axis represents all the loci and their positions are shown in the ‘Start’ column of the main table. The y axis represents the strains (with labels in the right hand section -3). Mouse over a loci to find the name of the locus, the allele number and the strain name. Loci are positioned by their co-occurrence in all the strains, in order of abundance. Hence, if a number of loci were found only in three particular strains, they would form a contiguous block towards the right of the graph. N.B. the order of loci on the graph does not necessarily reflect their order in any genome (to obtain this information see below). However, grouping by co-occurrence usually creates blocks that are analogous to extra chromosomal elements such as phages and plasmids.
The Controls for the graph are in the left hand menu panel (6). The x and y axis can be increased/decreased independently, but by using the mouse wheel allows zooming in and out is also possible. This panel also allows left and right scrolling, but scrolling in all directions can be achieved by dragging on the graph itself.
Obtaining More Information on Loci

Clicking on a locus will highlight the loci (1) and strain specific information (genomic location ,allele ID etc.) for all loci in the search will be shown in the table (2), with the name of strain being shown above the table (3). The actual locus clicked will be highlighted in the table (4). Clicking on the eye icon (5) for a locus will open up a genome viewer (JBrowse), which shows the position of that locus in the genome.
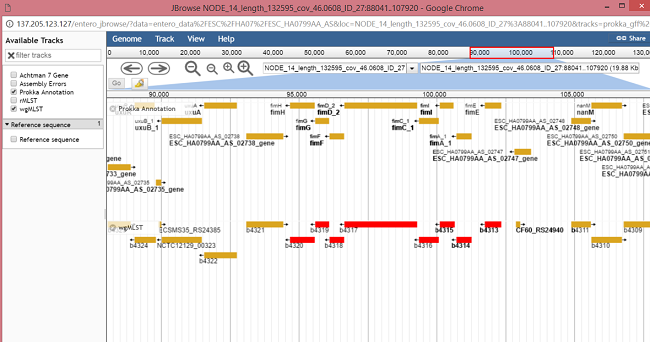
All loci in the locus search be red in the wgMLST track. The other track shown by default displays all the genes in the prokka annotation, which may contain genes that are not in the wgMLST scheme and will contain more information on each gene (locus). Depending on the type of genome, other tracks (selected from the left hand panel) will be available e.g Assembly Errors, GenBank Annotation, other schemes etc. If the genome has not been viewed before it will have to be formatted which will take a few seconds, so please be patient
Exporting Data
The ‘Matrix’ button above the table will download a matrix containing allele IDs for loci (columns) in all the strains (rows). Absent loci will have an allele ID of 0. ‘Save Data’ will download all the data present in the table
Creating A Sub-scheme
A sub-scheme (see User-Defined Content (Custom Views)) Can be created by checking the loci that you want in the main table and then pressing the ‘Make Sub Scheme’ button. A dialog will then appear which allows you to specify the name and location of the sub scheme (custom view), which can be viewed in the main search page